


1、openebs介绍
参考链接:
Kubernetes云原生存储解决方案openebs部署实践
2、helm部署openebs
2.1 完整安装
# 设置 Helm 存储库
helm repo add openebs https://openebs.github.io/openebs
更新helm repo update使用默认值安装 OpenEBS helm 图表helm install openebs --namespace openebs openebs/openebs --create-namespace上述命令将在命名空间和图表名称中安装 OpenEBS Local PV Hostpath、OpenEBS Local PV LVM、OpenEBS Local PV ZFS 和 OpenEBS Replicated Storage 组件2.2 部署openebs (禁用复制存储的安装)
部署openebs 不安装OpenEBS Replicaked Storage(禁用复制存储的安装)
helm install openebs --namespace openebs openebs/openebs --set engines.replicated.mayastor.enabled=false --create-namespace
(补充:helm安装)
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
chmod 700 get_helm.sh
./get_helm.sh
helm repo add bitnami https://charts.bitnami.com/bitnami
helm repo list
2.3 常见问题
2.3.1 openebs-etcd 中有 pod 一直处于 pending 状态
现象:
[root@k8s-master01 ~]# kubectl get pod -n openebs |grep etcd
openebs-etcd-0 0/1 Running 2 (11s ago) 10m
openebs-etcd-1 0/1 Pending 0 10m
openebs-etcd-2 0/1 Pending 0 10m
[root@k8s-master01 ~]# kubectl get pvc -n openebs
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
data-openebs-etcd-0 Bound pvc-f5fca73d-ed5f-4916-a581-1d3017f9a6c8 2Gi RWO mayastor-etcd-localpv <unset> 11m
data-openebs-etcd-1 Pending mayastor-etcd-localpv <unset> 11m
data-openebs-etcd-2 Pending mayastor-etcd-localpv <unset> 11m
storage-openebs-loki-0 Bound pvc-3a8adf01-7feb-42d0-a13d-dda1e1d6fcc9 10Gi RWO mayastor-loki-localpv <unset> 11m
etcd需要三个pod进行选主来实现
问题排查:
# 获取 openebs-etcd-0 describe 信息(提示:statefulset 控制器创建pod成功,但是pod中服务异常,导致 openebs-etcd-0 整个pod一直重建)
[root@k8s-master01 ~]# kubectl describe pod -n openebs openebs-etcd-0 |tail -n10
Normal Created 5m40s kubelet Created container volume-permissions
Normal Started 5m40s kubelet Started container volume-permissions
Normal Pulling 5m39s kubelet Pulling image "docker.io/bitnami/etcd:3.5.6-debian-11-r10"
Normal Pulled 5m5s kubelet Successfully pulled image "docker.io/bitnami/etcd:3.5.6-debian-11-r10" in 18.573s (34.397s including waiting)
Warning Unhealthy 113s kubelet Liveness probe failed:
Warning Unhealthy 113s kubelet Readiness probe failed:
Normal Created 87s (x4 over 5m5s) kubelet Created container etcd
Normal Started 87s (x4 over 5m5s) kubelet Started container etcd
Normal Pulled 87s (x3 over 4m4s) kubelet Container image "docker.io/bitnami/etcd:3.5.6-debian-11-r10" already present on machine
Warning BackOff 0s (x7 over 3m4s) kubelet Back-off restarting failed container etcd in pod openebs-etcd-0_openebs(359747cb-5592-433c-8717-525ab7b5bb9d)
获取 openebs-etcd-1、openebs-etcd-2的describe信息(提示: Pod 出现了FailedScheduling 错误,具体原因是调度器无法找到合适的节点。原因有:1、Pod 的反亲和性规则(anti-affinity rules)导致某些节点不匹配;2、节点上有未被容忍的污点(taint))
[root@k8s-master01 ~]# kubectl describe pod -n openebs openebs-etcd-1 | tail -n4
Events:
Type Reason Age From MessageWarning FailedScheduling 15s (x9 over 17m) default-scheduler 0/2 nodes are available: 1 node(s) didn’t match pod anti-affinity rules, 1 node(s) had untolerated taint {node-role.kubernetes.io/control-plane: }. preemption: 0/2 nodes are available: 1 No preemption victims found for incoming pod, 1 Preemption is not helpful for scheduling.
[root@k8s-master01 ~]# kubectl describe pod -n openebs openebs-etcd-2 | tail -n4
Events:
Type Reason Age From MessageWarning FailedScheduling 22s (x8 over 17m) default-scheduler 0/2 nodes are available: 1 node(s) didn’t match pod anti-affinity rules, 1 node(s) had untolerated taint {node-role.kubernetes.io/control-plane: }. preemption: 0/2 nodes are available: 1 No preemption victims found for incoming pod, 1 Preemption is not helpful for scheduling.解决方案如下:
# 1. 解决Pod 的反亲和性规则不匹配
# 获取pod反亲和性信息
[root@k8s-master01 ~]# kubectl get pod -n openebs openebs-etcd-0 -oyaml |grep -A7 affinity
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app.kubernetes.io/instance: openebs
app.kubernetes.io/name: etcd
topologyKey: kubernetes.io/hostname
# 直接删除所有反亲和性(由于openebs-etcd的pod有statefulset控制器创建,则需要从控制器测进行修改。直接删除即可)
[root@k8s-master01 ~]# kubectl edit statefulset -n openebs openebs-etcd
2. 解决节点被污点标记且 Pod 未容忍获取节点污点信息[root@k8s-master01 ~]# kubectl describe node |grep -i taint
Taints: node-role.kubernetes.io/control-plane:NoSchedule
Taints: <none>移除污点[root@k8s-master01 ~]# kubectl taint nodes k8s-master01 node-role.kubernetes.io/control-plane:NoSchedule-
node/k8s-master01 untainted
[root@k8s-master01 ~]# kubectl describe node |grep -i taint
Taints: <none>
Taints: <none>触发控制器重建pod[root@k8s-master01 ~]# kubectl rollout restart statefulset -n openebs openebs-etcd若一段时间 openebs-etcd仍然未正常,则删除所有 openebs-etcd的pod,手动触发重建[root@k8s-master01 ~]# for i in 0 1 2 ; do kubectl delete pod -n openebs openebs-etcd-$i ;done
2.3.2 openebs-csi 一直处于init状态
排查:
# 获取 openebs-csi 状态
[root@k8s-master01 ~]# kubectl get pod -n openebs|grep csi
openebs-csi-controller-647bb5575d-qkxqf 0/6 Init:0/1 0 18m
openebs-csi-node-krcg4 0/2 Init:0/1 0 18m
[root@k8s-master01 ~]# kubectl get all -n openebs |grep csi
pod/openebs-csi-controller-647bb5575d-qkxqf 0/6 Init:0/1 0 22m
pod/openebs-csi-node-krcg4 0/2 Init:0/1 0 22m
daemonset.apps/openebs-csi-node 1 1 0 1 0 kubernetes.io/arch=amd64 22m
deployment.apps/openebs-csi-controller 0/1 1 0 22m
replicaset.apps/openebs-csi-controller-647bb5575d 1 1 0 22m
$ kubectl describe pod/openebs-csi-controller-647bb5575d-qkxqf -n openebs |tail -n5
$ kubectl logs -f -n openebs openebs-csi-controller-647bb5575d-qkxqf |tail -n5
$ kubectl describe pod/openebs-csi-node-krcg4 -n openebs |tail -n5
$ kubectl logs -f pod/openebs-csi-node-krcg4 -n openebs |tail -n5结论:没有nvme_tcp模块,需要加载内核模块解决:
# 手动加载模块: 在各个节点上执行以下命令加载 nvme_tcp 模块:
$ modprobe nvme_tcp
自动加载模块: 将模块加载命令写入到配置文件中,以便在系统重启后自动加载:
$ echo "nvme_tcp" | sudo tee /etc/modules-load.d/openebs.conf
# 若出现如下报错,则需要升级内核解决
[root@k8s-master01 ~]# modprobe nvme_tcp
modprobe: FATAL: Module nvme_tcp not found.
拓展:centos7.9 升级内核至 4.18 版本以上
# 为 RHEL-7 SL-7 或 CentOS-7 安装 ELRepo
yum install https://www.elrepo.org/elrepo-release-7.el7.elrepo.noarch.rpm -y
sed -i "s@mirrorlist@#mirrorlist@g" /etc/yum.repos.d/elrepo.repo
sed -i "s@elrepo.org/linux@mirrors.tuna.tsinghua.edu.cn/elrepo@g" /etc/yum.repos.d/elrepo.repo
安装最新的内核我这里选择的是稳定版kernel-ml 如需更新长期维护版本kernel-lt# 仅下载内核到 /root/yum
yum -y --enablerepo=elrepo-kernel install kernel-ml --downloadonly --downloaddir=/root/yum/
# 通过阿里云安装
yum -y --enablerepo=elrepo-kernel install kernel-ml
# 通过局域网安装
yum -y install kernel-ml
查看已安装那些内核rpm -qa | grep kernel查看默认内核grubby --default-kernel若不是最新的使用命令设置grubby --set-default $(ls /boot/vmlinuz-* | grep elrepo)重启生效reboot
3、helm安装loki
(使用openebs创建的sc作为存储)
参考链接:
Grafana Loki笔记02: 使用Helm安装Loki
3.1 配置存储
创建一个values.yaml文件(修改部分角色的存储通过openebs创建的openebs-hostpath 来创建pvc)
$ cat values.yaml
loki:
schemaConfig:
configs:
- from: "2024-04-01"
store: tsdb
object_store: s3
schema: v13
index:
prefix: loki_index_
period: 24h
ingester:
chunk_encoding: snappy
querier:
# Default is 4, if you have enough memory and CPU you can increase, reduce if OOMing
max_concurrent: 4
pattern_ingester:
enabled: true
limits_config:
allow_structured_metadata: true
volume_enabled: true
deploymentMode: SimpleScalablebackend:
replicas: 2
persistence:
storageClass: openebs-hostpath
read:
replicas: 2
write:
replicas: 3 # To ensure data durability with replication
persistence:
storageClass: openebs-hostpathEnable minio for storageminio:
enabled: truegateway:
service:
type: LoadBalancer
ingress:
enabled: true
ingressClassName: nginx
annotations:
nginx.ingress.kubernetes.io/ssl-redirect: "false"
nginx.ingress.kubernetes.io/proxy-read-timeout: "3600"
nginx.ingress.kubernetes.io/proxy-send-timeout: "3600"
hosts:
- host: loki.example.com
paths:
- path: /
pathType: ImplementationSpecific
3.2 安装Loki
# helm 安装 Loki
helm install --values values.yaml loki grafana/loki --namespace log --create-namespace
3.3 curl测试
# 测试从k8s集群外部访问loki-gateway
$ curl --insecure https://loki.example.com/loki/api/v1/status/buildinfo
部署promtail,讲本机日志导入lokiwget https://github.com/grafana/loki/releases/download/v2.8.2/promtail-linux-amd64.zip
unzip promtail-linux-amd64.zip
mv promtail-linux-amd64 promtail创建一个配置文件,用于指定Promtail如何查找和发送日志$ cat promtail.yamlDisable the HTTP and GRPC server.server:
disable: truepositions:
filename: /tmp/positions.yamlclients:url: https://loki.example.com/loki/api/v1/push
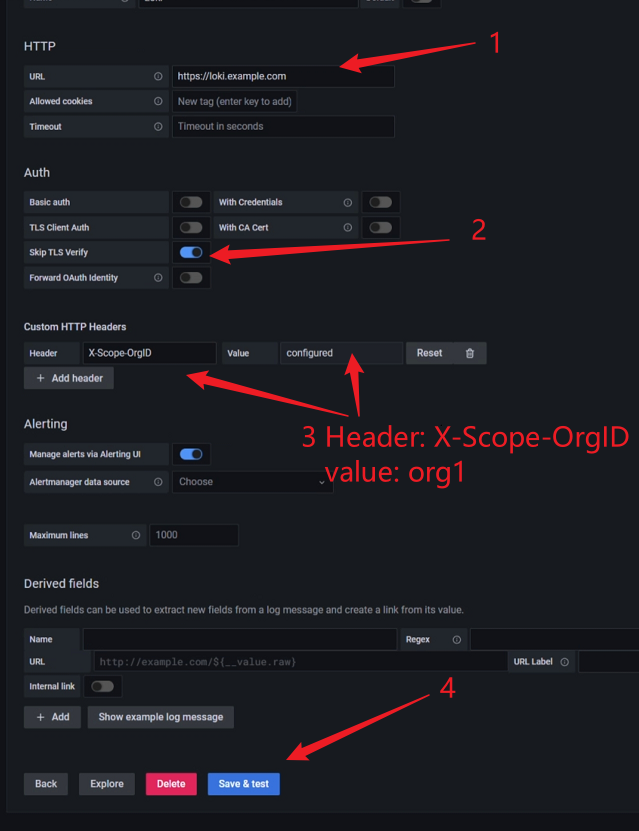
headers:
X-Scope-OrgID: org1scrape_configs:job_name: system
static_configs:
targets:
localhost
labels:
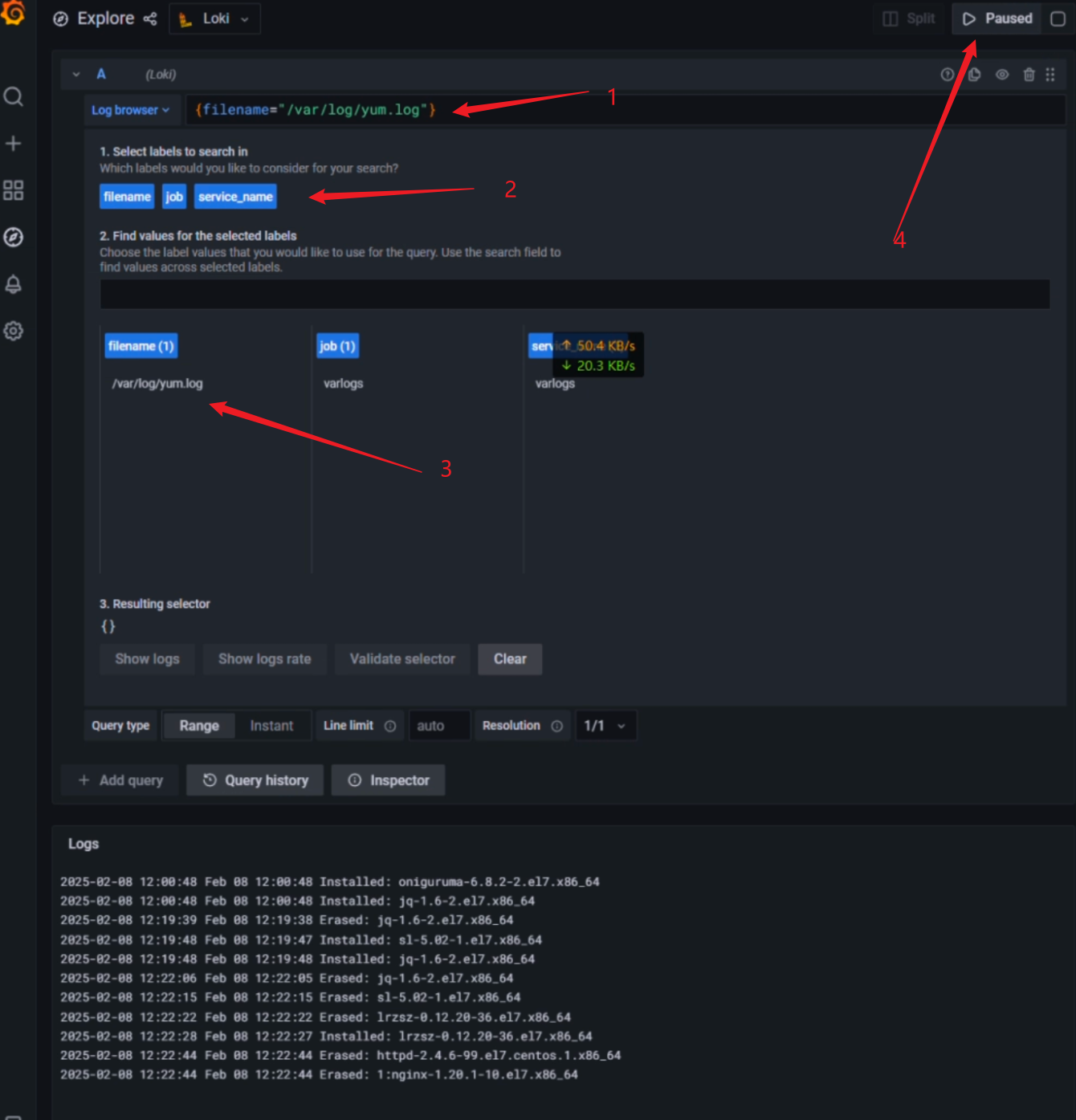
job: varlogs
path: /var/log/*log运行Promtail./promtail -config.file=promtail.yaml另起终端,先产生日志,再curl测试yum -y install nginx ;yum -y remove nginx
curl -H "X-Scope-OrgID: org1" https://loki.example.com/loki/api/v1/labels --insecure
curl -H "X-Scope-OrgID: org1" https://loki.example.com/loki/api/v1/label/job/values --insecure
curl -H "X-Scope-OrgID: org1" https://loki.example.com/loki/api/v1/label/job/values --insecure
curl -H "X-Scope-OrgID: org1" -G ‘https://loki.example.com/loki/api/v1/query_range’
–data-urlencode ‘query={job="varlogs"}’
–data-urlencode ‘since=1h’ --insecure
3.4 grafana配置loki源
==注意:需要配置hosts解析(使得grafana能解析到loki)==
grafana链接loki
日志验证
3.5 常见问题
# 需要修改 loki-write副本数 (loki-write需要至少两个副本才能正常运行)
$ kubectl edit statefulset -n log loki-write
# loki-chunks-cache-0 已知pending(修改statefulset控制器的资源限制)
Warning FailedScheduling 23s (x3 over 6m33s) default-scheduler 0/2 nodes are available: 2 Insufficient memory. preemption: 0/2 nodes are available: 2 No preemption victims found for incoming pod.
$ kubectl edit statefulset -n log loki-chunks-cache
# 删掉资源删除部分、或者根据实际资源情况调整资源限制部分
评论区