


项目概述
本方案基于Prometheus + Alertmanager + Grafana构建Kubernetes集群监控系统,主要包含以下组件:
Prometheus:负责指标数据采集与存储
Alertmanager:实现告警通知管理
Grafana:提供可视化监控仪表盘
Node Exporter:节点资源监控(已集成配置)
kube-state-metrics:Kubernetes资源对象状态监控
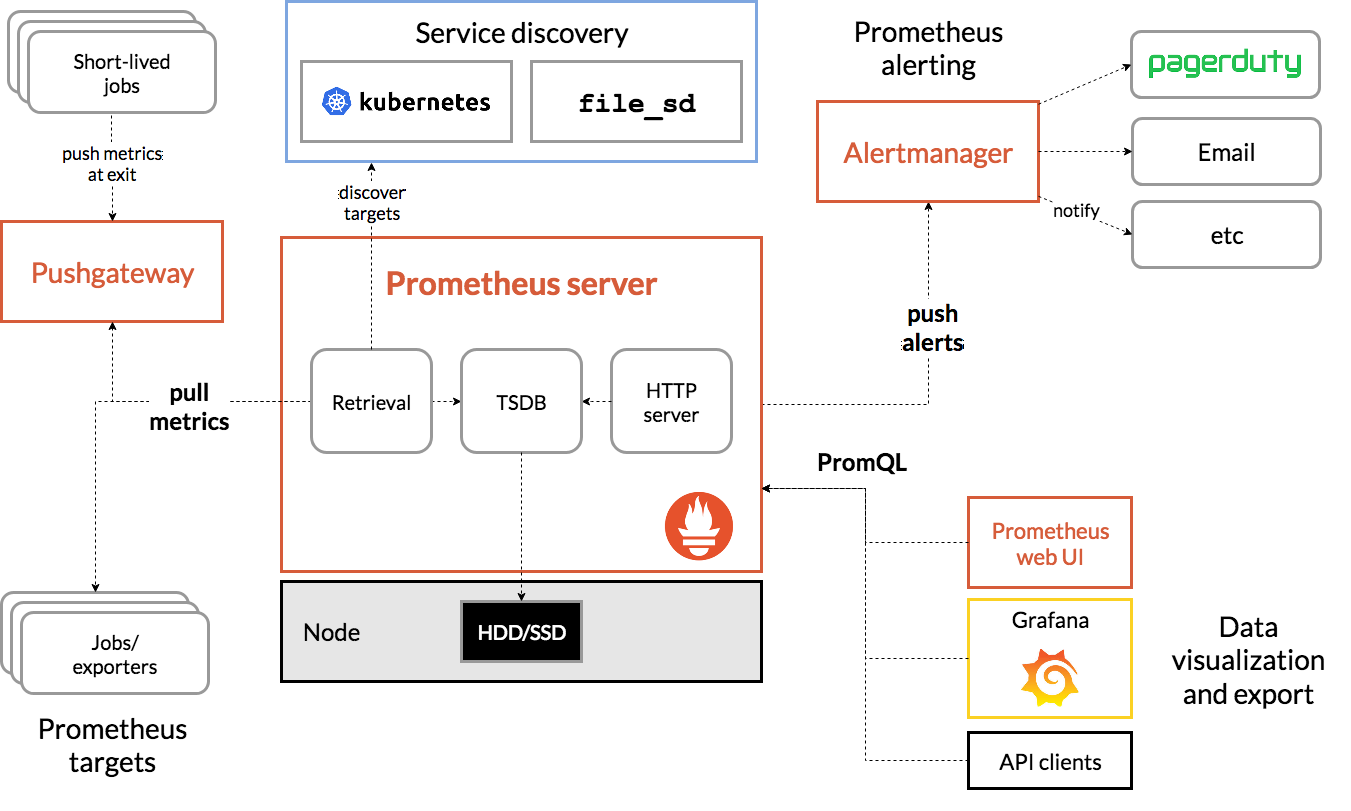
系统架构
前置条件
已部署Kubernetes集群(v1.18+)
已配置NFS存储服务及对应StorageClass
prometheus使用
nfs-csi存储类grafana使用
nfs-client存储类
准备有效的SMTP邮箱配置(用于告警通知)
文件结构说明
.
├── 00-ns-kube-ops.yaml # 命名空间配置
├── 01.prometheus-pvc.yaml # Prometheus存储声明
├── 02.prometheus-rbac.yaml # RBAC权限配置
├── 03.alertmanager-conf.yaml # Alertmanager配置
├── 04.prometheus-cm.yaml # Prometheus主配置
├── 05.prometheus-svc.yaml # 服务暴露配置
├── 06.promethus-alertmanager-deploy.yaml # 主部署文件
├── 08-grafana/ # Grafana组件
│ ├── 1.deployment.yaml
│ ├── 2.grafana-volume.yaml
│ ├── 3.grafana-svc.yaml
│ └── 4.grafana-chown-job.yaml
└── run.md # 辅助脚本
部署步骤
1. 创建命名空间
[root@k8s-master01 /root/k8s-1.27.1/prometheus/prometheus-node]# cat 00-ns-kube-ops.yaml
apiVersion: v1
kind: Namespace
metadata:
name: kube-ops
$ kubectl apply -f 00-ns-kube-ops.yaml
2. 部署Prometheus
# 创建存储卷
[root@k8s-master01 /root/k8s-1.27.1/prometheus/prometheus-node]# cat 01.prometheus-pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: prometheus
namespace: kube-ops
spec:
storageClassName: nfs-csi
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
$ kubectl apply -f 01.prometheus-pvc.yaml配置RBAC权限[root@k8s-master01 /root/k8s-1.27.1/prometheus/prometheus-node]# cat 02.prometheus-rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: kube-opsapiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:apiGroups:
""
resources:nodesservicesendpointspodsnodes/proxy
verbs:getlistwatchapiGroups:
""
resources:configmapsnodes/metrics
verbs:getnonResourceURLs:
/metrics
verbs:getapiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:kind: ServiceAccount
name: prometheus
namespace: kube-ops$ kubectl apply -f 02.prometheus-rbac.yaml创建Alertmanager配置[root@k8s-master01 /root/k8s-1.27.1/prometheus/prometheus-node]# cat 03.alertmanager-conf.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: alert-config
namespace: kube-ops
data:
config.yml: |-
global:
# 在没有报警的情况下声明为已解决的时间
resolve_timeout: 1m
# 配置邮件发送信息
smtp_smarthost: ‘smtp.163.com:25’
smtp_from: ‘123@163.com’
smtp_auth_username: ‘123’
smtp_auth_password: ‘123’
smtp_hello: ‘163.com’
smtp_require_tls: false
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 这里的标签列表是接收到报警信息后的重新分组标签,例如,接收到的报警信息里面有许多具有 cluster=A 和 alertname=LatncyHigh 这样的标签的报警信息将会批量被聚合到一个分组里面
group_by: [‘alertname’, ‘cluster’]
# 当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 30s # 当第一个报警发送后,等待'group_interval'时间来发送新的一组报警信息。
group_interval: 5m
# 如果一个报警信息已经发送成功了,等待'repeat_interval'时间来重新发送他们
repeat_interval: 5m
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: default
# 上面所有的属性都由所有子路由继承,并且可以在每个子路由上进行覆盖。
routes:
- receiver: email
group_wait: 10s
match:
team: node
receivers:
- name: 'default'
email_configs:
- to: '123@163.com'
send_resolved: true
- name: 'email'
email_configs:
- to: '123@163.com'
send_resolved: true
$ kubectl apply -f 03.alertmanager-conf.yaml创建Prometheus主配置[root@k8s-master01 /root/k8s-1.27.1/prometheus/prometheus-node]# cat 04.prometheus-cm.yaml修改 prometheus 配置文件,prometheus-cm.yamlapiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-ops
data:
prometheus.yml: |
global:
scrape_interval: 30s
scrape_timeout: 30sscrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'pve-node'
metrics_path: /metrics
static_configs:
- targets: ['192.168.2.9:9100', '192.168.2.17:9100', '192.168.2.18:9100', '192.168.2.19:9100', '192.168.2.20:9100']
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"]
$ kubectl apply -f 04.prometheus-cm.yaml部署主服务[root@k8s-master01 /root/k8s-1.27.1/prometheus/prometheus-node]# cat 05.prometheus-svc.yaml修改 prometheus service 文件, prometheus-svc.yamlapiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: kube-ops
labels:
app: prometheus
spec:
selector:
app: prometheus
type: NodePort
ports:
- name: web
port: 9090
targetPort: http
- name: altermanager
port: 9093
targetPort: 9093
$ kubectl apply -f 05.prometheus-svc.yaml[root@k8s-master01 /root/k8s-1.27.1/prometheus/prometheus-node]# cat 06.promethus-alertmanager-deploy.yaml合并 altermanager 至 prometheus deploy 文件apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
namespace: kube-ops
labels:
app: prometheus
spec:
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
serviceAccountName: prometheus
containers:
- name: alertmanager
image: prom/alertmanager:v0.15.3
imagePullPolicy: IfNotPresent
args:
- "–config.file=/etc/alertmanager/config.yml"
- "–storage.path=/alertmanager/data"
ports:
- containerPort: 9093
name: alertmanager
volumeMounts:
- mountPath: "/etc/alertmanager"
name: alertcfg
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 100m
memory: 256Mi
- image: prom/prometheus:v2.4.3
name: prometheus
command:
- "/bin/prometheus"
args:
- "–config.file=/etc/prometheus/prometheus.yml"
- "–storage.tsdb.path=/prometheus"
- "–storage.tsdb.retention=24h"
- "–web.enable-admin-api" # 控制对admin HTTP API的访问,其中包括删除时间序列等功能
- "–web.enable-lifecycle" # 支持热更新,直接执行localhost:9090/-/reload立即生效
ports:
- containerPort: 9090
protocol: TCP
name: http
volumeMounts:
- mountPath: "/prometheus"
subPath: prometheus
name: data
- mountPath: "/etc/prometheus"
name: config-volume
resources:
requests:
cpu: 100m
memory: 512Mi
limits:
cpu: 1000m
memory: 2048Mi
securityContext:
runAsUser: 0
volumes:
- name: data
persistentVolumeClaim:
claimName: prometheus
- configMap:
name: prometheus-config
name: config-volume
- name: alertcfg
configMap:
name: alert-config$ kubectl apply -f 06.promethus-alertmanager-deploy.yaml
3. 部署Grafana
# 进入grafana目录
cd 08-grafana
按顺序部署组件kubectl apply -f 2.grafana-volume.yaml
kubectl apply -f 1.deployment.yaml
kubectl apply -f 4.grafana-chown-job.yaml # 权限修复
kubectl apply -f 3.grafana-svc.yaml
配置说明
Prometheus配置
数据保留时间:24小时
监控目标:
PVE节点:192.168.2.9:9100等
Kubernetes API资源
热更新方式:
curl -X POST "http://<PROMETHEUS_SERVICE_IP>:9090/-/reload"
Alertmanager配置
使用163邮箱发送告警
告警分组策略:
按alertname和cluster分组
初始等待时间30秒
重复间隔5分钟
Grafana配置
数据存储:/var/lib/grafana(持久化存储)
自动挂载NFS存储并修复权限
访问方式
维护指南
配置更新流程
修改对应ConfigMap
kubectl edit cm -n kube-ops prometheus-config执行热更新
curl -X POST "http://<Prometheus_IP>:9090/-/reload"
数据持久化
Prometheus数据:存储在nfs-csi PV,10GiB空间
Grafana数据:存储在nfs-client PV,1GiB空间
常见问题排查
Pod启动失败:
检查PVC绑定状态:
kubectl get pvc -n kube-ops查看Pod日志:
kubectl logs -f <pod-name> -n kube-ops
告警邮件未发送:
验证Alertmanager配置:
kubectl describe cm alert-config -n kube-ops检查SMTP认证信息是否正确
Grafana无法登录:
确认权限修复Job已执行成功
检查存储卷挂载状态
安全建议
生产环境建议:
修改默认Grafana密码
启用HTTPS访问
限制NodePort访问范围
定期备份重要配置
邮件配置建议:
使用专用告警邮箱
启用SMTP TLS加密
定期轮换SMTP密码
评论区