7 Kubernetes-调度器和调度算法
决定 pod 在具体哪个节点中运行。比如,有些pod对节点的GPU、磁盘类型有要求
一、调度说明
1、scheduler为 Kubernetes 的调度器
创建pod时,处于pending状态,即等待 scheduler 决定调度到哪个节点中运行
scheduler 的调度需要考虑:公平、资源高效利用、效率调度、灵活调度
1.公平:保证每个节点都能分配到资源
2.资源高效利用:集群所有资源最大化利用
3.效率:调度有效率性,尽快处理大量pod的调度
4.灵活:让用户根据自己需求,在指定节点中运行
2、调度过程
注意:满足所有算法,才能通过选择
1)预选(排除不满足要求的节点)
常用算法:资源、NodeName、port、Label、Volume
PodFitsResources:节点上剩余的资源是否大于 pod 请求的资源PodFitsHost:如果 pod 指定了 NodeName,检查节点名称是否和 NodeName 匹配PodFitsHostPorts:节点上已经使用的 port 是否和 pod 申请的 port 冲突PodSelectorMatches:过滤掉和 pod 指定的 label 不匹配的节点NoDiskConflict:已经 mount 的 volume 和 pod 指定的 volume 不冲突,除非它们都是只读
2)优选(从满足的节点中,进行排序,选择最优的)
常用算法:使用率、接近率、总数(权重越高、越优)
LeastRequestedPriority:CPU和MEM的使用率,使用率越低,权重越高BalancedResourceAllocation:CPU和MEM使用率的接近率,接近率越低,权重越高ImageLocalityPriority:节点镜像总数,总数越高,权重越高
3、定义调度器
除了 kubernetes 自带的调度器,你也可以编写自己的调度器。通过 spec:schedulername 参数指定调度器的名字,可以为 pod 选择某个调度器进行调度。(一般不用,官方调度器已经够优秀)
apiVersion: v1
kind: Pod
metadata:
name: test-scheduler
labels:
name: test-scheduler
spec:
schedulername: test-scheduler
containers:
- name: pod-with-second-annotation-container
image: wangyanglinux/myapp:v2
下面介绍调度的灵活性
二、调度亲和性
1、节点亲和性
pod.spec.affinity.nodeAffinity
- preferredDuringSchedulingIgnoredDuringExecution:软策略(满足则运行,不满足也会运行)
软策略有权重的原因:若有多个亲和性,设置权重,根据权重选择(若只有一个亲和,不设置权重,默认为1)
- requiredDuringSchedulingIgnoredDuringExecution:硬策略(满足才会运行,不满足不运行)
拓展:给节点添加标签
$ kubectl label node k8s-node01 disktype=sshd
键值运算关系
- In:label 的值在某个列表中
- NotIn:label 的值不在某个列表中
- Gt:label 的值大于某个值
- Lt:label 的值小于某个值
- Exists:某个 label 存在
- DoesNotExist:某个 label 不存在
如果nodeSelectorTerms下面有多个选项的话,满足任何一个条件就可以了
如果matchExpressions有多个选项的话,则必须同时满足这些条件才能正常调度 POD
1)实验1:节点亲和性---硬策略
实验步骤:
[root@k8s-master01 6]# vim 1.pod.yaml
[root@k8s-master01 6]# cat 1.pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: affinity
labels:
app: node-affinity-pod
spec:
containers:
- name: with-node-affinity
image: wangyanglinux/myapp:v1
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: NotIn
values:
- k8s-node02
[root@k8s-master01 6]# kubectl apply -f 1.pod.yaml
pod/affinity created
[root@k8s-master01 6]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
affinity 1/1 Running 0 6s 172.100.1.185 k8s-node01 <none> <none>
[root@k8s-master01 6]#
# 更改硬策略为:在 kubernetes.io/hostname=k8s-node03 的节点上运行(若没有,则不运行)
[root@k8s-master01 6]# cp -a 1.pod.yaml 1.1.pod.yaml
[root@k8s-master01 6]# vim 1.1.pod.yaml
[root@k8s-master01 6]# cat 1.1.pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: affinity
labels:
app: node-affinity-pod
spec:
containers:
- name: with-node-affinity
image: wangyanglinux/myapp:v1
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- k8s-node03
[root@k8s-master01 6]# kubectl delete pod affinity
[root@k8s-master01 6]# kubectl apply -f 1.1.pod.yaml
pod/affinity created
[root@k8s-master01 6]# kubectl get pod
NAME READY STATUS RESTARTS AGE
affinity 0/1 Pending 0 2m3s
2)实验2:节点亲和性---软策略
实验步骤:
# 1、给节点设置一个新的标签
[root@k8s-master01 6]# kubectl label node k8s-node01 disktype=sshd
[root@k8s-master01 6]# kubectl get node -o wide --show-labels |grep sshd
k8s-node01 Ready <none> 24d v1.15.1 192.168.20.202 <none> CentOS Linux 7 (Core) 4.4.222-1.el7.elrepo.x86_64 docker://20.10.22 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disktype=sshd,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node01,kubernetes.io/os=linux
# 2、运行一个pod,亲和性为软策略,匹配disktype=sshd的节点
[root@k8s-master01 6]# vim 2.pod.yaml
[root@k8s-master01 6]# cat 2.pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: preferredaffinity
labels:
app: node-affinity-pod
spec:
containers:
- name: with-node-affinity
image: wangyanglinux/myapp:v1
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: disktype
operator: In
values:
- sshd
# 3、写一个死循环,发现pod一直在node01节点创建
[root@k8s-master01 6]# while true;do kubectl apply -f 2.pod.yaml && kubectl get pod -o wide && kubectl delete -f 2.pod.yaml ;done
pod/preferredaffinity created
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
affinity 0/1 Pending 0 30m <none> <none> <none> <none>
preferredaffinity 0/1 ContainerCreating 0 0s <none> k8s-node01 <none> <none>
pod "preferredaffinity" deleted
pod/preferredaffinity created
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
affinity 0/1 Pending 0 30m <none> <none> <none> <none>
preferredaffinity 0/1 ContainerCreating 0 0s <none> k8s-node01 <none> <none>
.....
# 4、修改2.pod.yaml 文件,将软亲和改为匹配 disktype=ssd 的节点
[root@k8s-master01 6]# vim 2.2.pod.yaml
[root@k8s-master01 6]# cat 2.2.pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: preferredaffinity
labels:
app: node-affinity-pod
spec:
containers:
- name: with-node-affinity
image: wangyanglinux/myapp:v1
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: disktype
operator: In
values:
- ssd
# 匹配不到运算符,可能会在别的节点运行(受多个因素影响,由调度器根据优选和预选决定)
[root@k8s-master01 6]# while true;do kubectl apply -f 2.2.pod.yaml && kubectl get pod -o wide && kubectl delete -f 2.2.pod.yaml ;done
pod/preferredaffinity created
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
preferredaffinity 0/1 ContainerCreating 0 0s <none> k8s-node01 <none> <none>
pod "preferredaffinity" deleted
pod/preferredaffinity created
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
preferredaffinity 0/1 ContainerCreating 0 0s <none> k8s-node01 <none> <none>
pod "preferredaffinity" deleted
pod/preferredaffinity created
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
preferredaffinity 0/1 ContainerCreating 0 0s <none> k8s-node02 <none> <none>
pod "preferredaffinity" deleted
3)实验3:节点亲和性---软、硬策略
(以硬策略为准)
实验步骤:
[root@k8s-master01 6]# vim 3.pod.yaml
[root@k8s-master01 6]# cat 3.pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: affinity
labels:
app: node-affinity-pod
spec:
containers:
- name: with-node-affinity
image: wangyanglinux/myapp:v1
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: NotIn
values:
- k8s-node02
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: source
operator: In
values:
- qikqiak
[root@k8s-master01 6]# while true;do kubectl apply -f 3.pod.yaml && kubectl get pod -o wide && kubectl delete -f 3.pod.yaml;done
pod/affinity created
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
affinity 0/1 ContainerCreating 0 0s <none> k8s-node01 <none> <none>
pod "affinity" deleted
pod/affinity created
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
affinity 0/1 ContainerCreating 0 0s <none> k8s-node01 <none> <none>
pod "affinity" deleted
pod/affinity created
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
affinity 0/1 ContainerCreating 0 0s <none> k8s-node01 <none> <none>
pod "affinity" deleted
pod/affinity created
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
affinity 0/1 ContainerCreating 0 0s <none> k8s-node01 <none> <none>
pod "affinity" deleted
pod/affinity created
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
affinity 0/1 ContainerCreating 0 0s <none> k8s-node01 <none> <none>
pod "affinity" deleted
2、pod亲和性
pod.spec.affinity.podAffinity (pod亲和性)
pod.spec.affinity.podAntiAffinity (pod反亲和性)
- requiredDuringSchedulingIgnoredDuringExecution:硬策略
- preferredDuringSchedulingIgnoredDuringExecution:软策略
亲和性/反亲和性调度策略比较如下:
| 调度策略 | 匹配标签 | 操作符 | 拓扑域支持 | 调度目标 |
|---|---|---|---|---|
| nodeAffinity | 主机 | In, NotIn, Exists, DoesNotExist, Gt, Lt | 否 | 指定主机 |
| podAffinity | POD | In, NotIn, Exists, DoesNotExist | 是 | POD与指定POD同一拓扑域 |
| podAnitAffinity | POD | In, NotIn, Exists, DoesNotExist | 是 | POD与指定POD不在同一拓扑域 |
**过程:**先寻找是否有匹配的pod存在
若存在,则根据pod所在节点,由定义的拓扑域(topologykey),寻找相同的拓扑域所在节点
则找出的节点,均可运行
**拓扑域:**由 topologykey 选项定义
topologyKey: kubernetes.io/hostname
topologyKey: disktype
实验步骤:
1、首先创建有pod硬亲和性的pod
[root@k8s-master01 6]# vim 4.pod.yaml
[root@k8s-master01 6]# cat 4.pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-3
labels:
app: pod-3
spec:
containers:
- name: pod-3
image: wangyanglinux/myapp:v1
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- pod-1
topologyKey: disktype
[root@k8s-master01 6]# kubectl apply -f 4.pod.yaml
# 发现pod无法创建,因为没有匹配的pod存在
[root@k8s-master01 6]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pod-3 0/1 Pending 0 21s
2、创建一个测试的pod,并匹配标签app=pod-1
[root@k8s-master01 6]# vim 5.test.yaml
[root@k8s-master01 6]# cat 5.test.yaml
apiVersion: v1
kind: Pod
metadata:
name: test
labels:
app: pod-1
spec:
containers:
- name: test
image: wangyanglinux/myapp:v1
[root@k8s-master01 6]# kubectl apply -f 5.test.yaml
# 发现有pod亲和性的标签正常运行
[root@k8s-master01 6]# kubectl get pod
NAME READY STATUS RESTARTS AGE
pod-3 1/1 Running 0 2m34s
test 1/1 Running 0 78s
3、测试拓扑域选择
先给node02节点添加disktype的key,前面已经给node01添加disktype
[root@k8s-master01 6]# kubectl label node k8s-node02 disktype=sshh
[root@k8s-master01 6]# kubectl get node --show-labels|grep disktype
k8s-node01 Ready <none> 24d v1.15.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disktype=sshd,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node01,kubernetes.io/os=linux
k8s-node02 Ready <none> 24d v1.15.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disktype=sshd,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node02,kubernetes.io/os=linux
# 利用循环,测试亲和性pod的选择(有拓扑域影响,可以在node01、node02上运行;也有调度器的预选优选的影响)
[root@k8s-master01 6]# kubectl delete pod pod-3
[root@k8s-master01 6]# while true;do kubectl apply -f 4.pod.yaml && kubectl get pod -o wide && kubectl delete -f 4.pod.yaml ;done
pod/pod-3 created
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-3 0/1 ContainerCreating 0 1s <none> k8s-node02 <none> <none>
test 1/1 Running 0 30s 172.100.1.64 k8s-node01 <none> <none>
pod "pod-3" deleted
pod/pod-3 created
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-3 0/1 ContainerCreating 0 0s <none> k8s-node01 <none> <none>
test 1/1 Running 0 37s 172.100.1.64 k8s-node01 <none> <none>
pod "pod-3" deleted
pod/pod-3 created
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-3 0/1 ContainerCreating 0 0s <none> k8s-node02 <none> <none>
test 1/1 Running 0 39s 172.100.1.64 k8s-node01 <none> <none>
pod "pod-3" deleted
3、pod反亲和性
比如:避免两个数据库在同一个节点运行
# 1、清理所有pod,避免影响
[root@k8s-master01 6]# kubectl delete pod --all
# 2、新建test的pod,并运行,查看在哪个节点运行
[root@k8s-master01 6]# vim 5.test.yaml
[root@k8s-master01 6]# cat 5.test.yaml
apiVersion: v1
kind: Pod
metadata:
name: test
labels:
app: pod-1
spec:
containers:
- name: test
image: wangyanglinux/myapp:v1
[root@k8s-master01 6]# kubectl apply -f 5.test.yaml
pod/test created
[root@k8s-master01 6]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test 1/1 Running 0 5s 172.100.1.92 k8s-node01 <none> <none>
# 3、新建pod-3的pod,利用pod反亲和性,与test的pod分开
[root@k8s-master01 6]# vim 6.pod.yaml
[root@k8s-master01 6]# cat 6.pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-3
labels:
app: pod-3
spec:
containers:
- name: pod-3
image: wangyanglinux/myapp:v1
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- pod-1
topologyKey: disktype
[root@k8s-master01 6]# kubectl apply -f 6.pod.yaml && kubectl get pod -o wide
pod/pod-3 created
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-3 0/1 ContainerCreating 0 0s <none> k8s-node02 <none> <none>
test 1/1 Running 0 32s 172.100.1.92 k8s-node01 <none> <none>
# 发现新建的pod,与test的pod不在同一个节点。验证了pod反亲和性
注意:存在节点亲和性和pod亲和性的原因
节点亲和性,只是相对于节点亲和。而pod亲和性,相对于pod亲和
比如:pod-nginx运行在node01
若pod-php-fpm与node01亲和,当pod-nginx重建运行在node02 。而pod-php-fpm重建后仍在node01
若pod-php-fpm与pod-nginx亲和,当pod-nginx重建运行在node02,相应的,pod-php-fpm重建后也会到node02
亲和性/反亲和性调度策略比较如下:
| 调度策略 | 匹配标签 | 操作符 | 拓扑域支持 | 调度目标 |
|---|---|---|---|---|
| nodeAffinity | 主机 | In, NotIn, Exists, DoesNotExist, Gt, Lt | 否 | 指定主机 |
| podAffinity | POD | In, NotIn, Exists, DoesNotExist | 是 | POD与指定POD同一拓扑域 |
| podAnitAffinity | POD | In, NotIn, Exists, DoesNotExist | 是 | POD与指定POD不在同一拓扑域 |
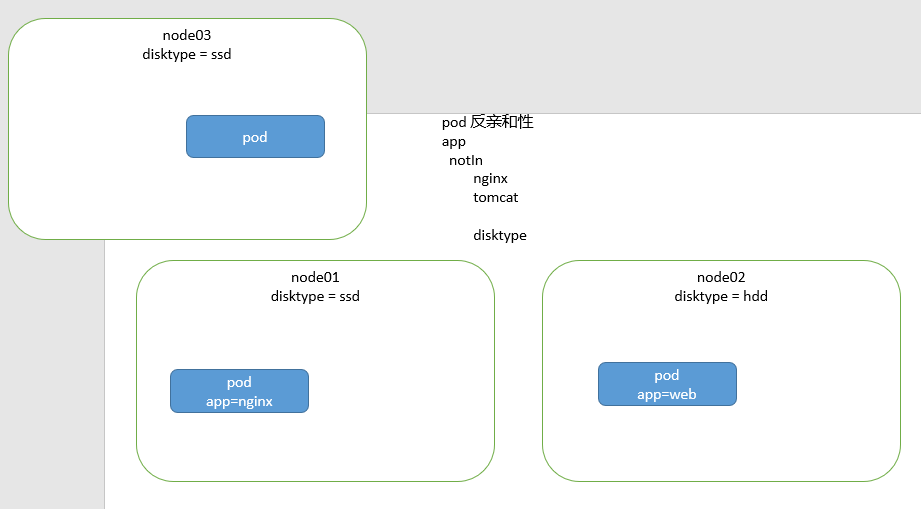
注意:pod的反亲和性与 NotIn 运算符结合
(并非简单的双重否定表肯定)
1.由运算符匹配不在列表的pod
2.再利用反亲和性,找到pod对应所在的节点
3.根据节点的拓扑域,进行选择pod运行所在节点
三、污点、容忍
**解决:**默认不在特殊节点上运行pod的情况。比如:默认不在有GPU节点上运行pod
在有GPU节点上设置污点。若需要运行在GPU节点上,需要忍受污点,还有其他因素决定(比如:预选、优选、有节点硬亲和)
**注意:**污点并不一定是差的
1、污点---Taint
使节点排斥一类特定的pod
若容忍污点以后,还需要预选、优选决定
1)当前 taint effect 支持的三个选项:
NoSchedule:不调度,不会被调度的节点,除非pod设置容忍此选项PreferNoSchedule:尽量不被调度的节点( K8S 中master高可用时,可以设置)NoExecute:不运行pod的节点(常用于节点的更新、升级、维护等)
2)二进制、容器化安装 K8S 的核心区别
二进制安装后,在master节点没有:容器运行时(CRI)、kubelet、kube-proxy,无法运行pod
容器化安装后,所有组件都是基于pod运行,所以存在容器运行时(CRI)、kubelet、kube-proxy,可以运行pod
3)实验1:污点的设置、查看、去除
核心命令:
# 设置污点
kubectl taint nodes node1 key1=value1:NoSchedule
# 节点说明中,查找 Taints 字段
kubectl describe pod pod-name
# 去除污点
kubectl taint nodes node1 key1:NoSchedule-
实验步骤:
在master节点中,存在一个污点
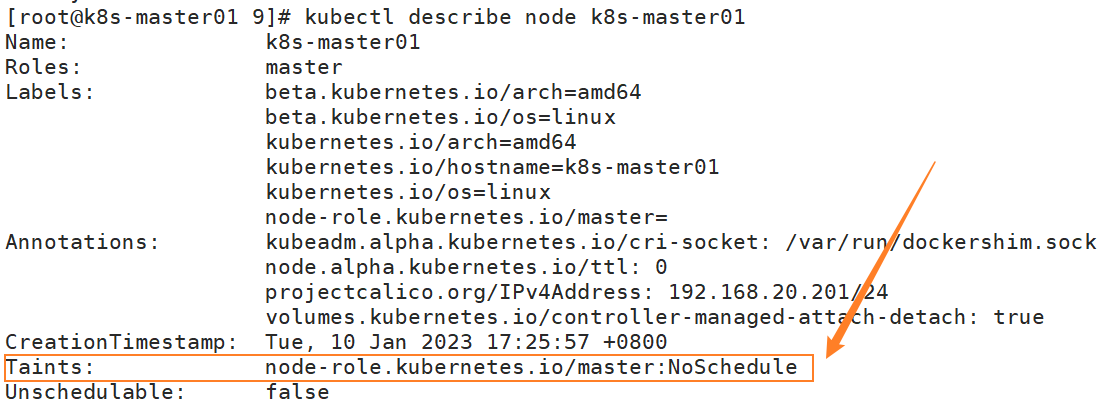
Ⅰ、查看master节点的污点
[root@k8s-master01 ~]# mkdir 9;cd 9
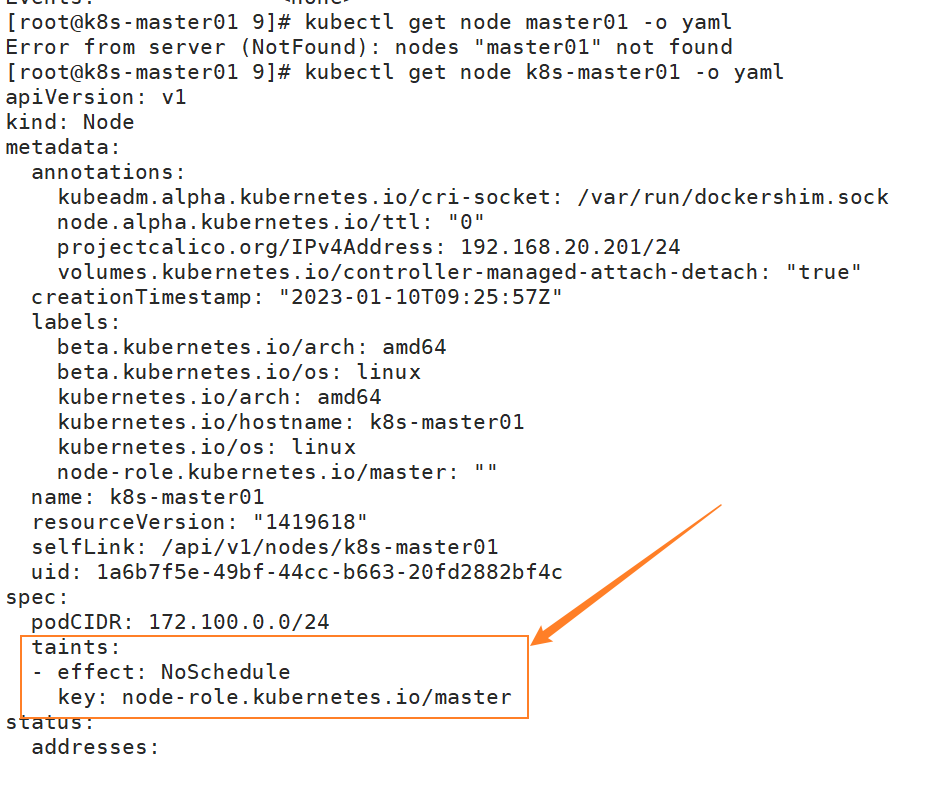
$ kubectl describe node k8s-master01
$ kubectl get node k8s-master01 -o yaml
Ⅱ、去除master污点
# 去除master的污点
[root@k8s-master01 9]# kubectl taint node k8s-master01 node-role.kubernetes.io/master=:NoSchedule-
[root@k8s-master01 9]# kubectl describe node k8s-master01 |grep Taint
Taints: <none>
# 创建deployment控制器,修改控制器副本数量,查看pod会在master节点运行
[root@k8s-master01 9]# kubectl create deployment myapp --image=wangyanglinux/myapp:v1
[root@k8s-master01 9]# kubectl scale deployment myapp --replicas=10
[root@k8s-master01 9]# kubectl get pod -o wide |grep master01
myapp-69cd984b7b-6rr58 1/1 Running 0 70s 172.100.0.4 k8s-master01 <none> <none>
myapp-69cd984b7b-tt9bn 1/1 Running 0 70s 172.100.0.5 k8s-master01 <none> <none>
myapp-69cd984b7b-w5n6c 1/1 Running 0 70s 172.100.0.3 k8s-master01 <none> <none>
myapp-69cd984b7b-wvcsw 1/1 Running 0 70s 172.100.0.2 k8s-master01 <none> <none>
Ⅲ、设置master的污点
[root@k8s-master01 9]# kubectl taint node k8s-master01 node-role.kubernetes.io/master=:NoSchedule
node/k8s-master01 tainted
[root@k8s-master01 9]# kubectl describe node k8s-master01|grep Taint
Taints: node-role.kubernetes.io/master:NoSchedule
4)实验2:测试 noscheduler、preferscheduler
Ⅰ、测试noscheduler
# 给k8s-node01设置污点
[root@k8s-master01 9]# kubectl taint node k8s-node01 key=:NoSchedule
[root@k8s-master01 9]# kubectl describe node k8s-node01 |grep Taint
Taints: key:NoSchedule
# 清理刚才创建的控制器
[root@k8s-master01 9]# kubectl delete deployment --all
# 新建控制器
[root@k8s-master01 9]# kubectl create deployment myapp --image=wangyanglinux/myapp:v1
# 修改控制器副本数量
[root@k8s-master01 9]# kubectl scale deployment myapp --replicas=10
# 查看pod运行的所在节点,在node01中没有运行pod
[root@k8s-master01 9]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp-69cd984b7b-2w7tf 1/1 Running 0 6s 172.100.2.223 k8s-node02 <none> <none>
myapp-69cd984b7b-5lrg5 1/1 Running 0 6s 172.100.2.222 k8s-node02 <none> <none>
myapp-69cd984b7b-84n4x 1/1 Running 0 6s 172.100.2.218 k8s-node02 <none> <none>
myapp-69cd984b7b-8gg7z 1/1 Running 0 6s 172.100.2.224 k8s-node02 <none> <none>
myapp-69cd984b7b-8x798 1/1 Running 0 6s 172.100.2.221 k8s-node02 <none> <none>
myapp-69cd984b7b-9btkt 1/1 Running 0 6s 172.100.2.220 k8s-node02 <none> <none>
myapp-69cd984b7b-c654l 1/1 Running 0 6s 172.100.2.225 k8s-node02 <none> <none>
myapp-69cd984b7b-qzdft 1/1 Running 0 33s 172.100.2.217 k8s-node02 <none> <none>
myapp-69cd984b7b-rmk72 1/1 Running 0 6s 172.100.2.219 k8s-node02 <none> <none>
myapp-69cd984b7b-szhhr 1/1 Running 0 6s 172.100.2.226 k8s-node02 <none> <none>
[root@k8s-master01 9]# kubectl get pod -o wide |grep node01
Ⅱ、测试preferscheduler
注意:污点不能直接修改,只能先删除已经存在的污点,在创建不同effect的污点
# 清理刚才设置的effect
[root@k8s-master01 9]# kubectl taint node k8s-node01 key=:NoSchedule-
# 设置新的effect PreferNoSchedule
[root@k8s-master01 9]# kubectl taint node k8s-node01 key=:PreferNoSchedule
# 检查设置的effect
[root@k8s-master01 9]# kubectl describe node k8s-node01 |grep Taint
Taints: key:PreferNoSchedule
# 清理刚才创建的控制器
[root@k8s-master01 9]# kubectl delete deployment --all
# 新建控制器
[root@k8s-master01 9]# kubectl create deployment myapp --image=wangyanglinux/myapp:v1
# 改变副本数量
[root@k8s-master01 9]# kubectl scale deployment myapp --replicas=10
# 查看pod运行的所在节点
[root@k8s-master01 9]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp-69cd984b7b-5ghk6 1/1 Running 0 3s 172.100.2.238 k8s-node02 <none> <none>
myapp-69cd984b7b-8qh9l 1/1 Running 0 3s 172.100.2.236 k8s-node02 <none> <none>
myapp-69cd984b7b-8rcqz 1/1 Running 0 3s 172.100.1.107 k8s-node01 <none> <none>
myapp-69cd984b7b-djl7s 1/1 Running 0 3s 172.100.1.109 k8s-node01 <none> <none>
myapp-69cd984b7b-f6xjk 1/1 Running 0 3s 172.100.2.235 k8s-node02 <none> <none>
myapp-69cd984b7b-gzcdr 1/1 Running 0 3s 172.100.1.110 k8s-node01 <none> <none>
myapp-69cd984b7b-hphss 1/1 Running 0 13s 172.100.2.233 k8s-node02 <none> <none>
myapp-69cd984b7b-qxjwk 1/1 Running 0 3s 172.100.1.108 k8s-node01 <none> <none>
myapp-69cd984b7b-wtbvv 1/1 Running 0 3s 172.100.2.237 k8s-node02 <none> <none>
myapp-69cd984b7b-x9gld 1/1 Running 0 3s 172.100.2.234 k8s-node02 <none> <none>
# 发现在node01节点会运行pod
[root@k8s-master01 9]# kubectl get pod -o wide |grep node01|wc -l
4
2、容忍---tolerations
pod.spec.tolerations
# 案例解释
tolerations: # 设置容忍
- key: "key1" # 当key1=value1,且effect为:NoSchedule,进行容忍
operator: "Equal"
value: "value1"
effect: "NoSchedule"
- key: "key1" # 当key1=value1,且effect为:NoExecute,进行容忍,在3600秒内,需要将节点中运行的pod转移到别的节点
operator: "Equal"
value: "value1"
effect: "NoExecute"
tolerationSeconds: 3600
- key: "key2" # 当key2存在时,且effect为NoSchedule,进行容忍
operator: "Exists"
effect: "NoSchedule"
1)常用设置
Ⅰ、只要有污点,都容忍
tolerations:
- operator: "Exists"
Ⅱ、当不指定 effect 值时,表示容忍所有的污点作用
tolerations:
- key: "key"
operator: "Exists"
Ⅲ、有多个 Master 存在时,防止资源浪费,可以如下设置
kubectl taint nodes Node-Name node-role.kubernetes.io/master=:PreferNoSchedule
2)实验1:测试 daemonset 控制器容忍master节点
daemonset控制器:在每个节点,有且仅有的运行一个pod
# 容忍的核心部分
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
实验步骤:
[root@k8s-master01 9]# vim 1.daemonset.yaml
[root@k8s-master01 9]# cat 1.daemonset.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: deamonset-example
labels:
app: daemonset
spec:
selector:
matchLabels:
name: deamonset-example
template:
metadata:
labels:
name: deamonset-example
spec:
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: daemonset-example
image: wangyanglinux/myapp:v1
[root@k8s-master01 9]# kubectl apply -f 1.daemonset.yaml
daemonset.apps/deamonset-example created
[root@k8s-master01 9]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deamonset-example-754ff 1/1 Running 0 5s 172.100.0.6 k8s-master01 <none> <none>
deamonset-example-ndv5r 1/1 Running 0 5s 172.100.2.239 k8s-node02 <none> <none>
deamonset-example-w6rbq 1/1 Running 0 5s 172.100.1.111 k8s-node01 <none> <none>
3)实验2:让pod仅在设置对应污点的节点运行
容忍污点后,还需进行预选、优选,若让pod仅在设置对应污点的节点运行,结合亲和性
# 1、清理之前创建的deployment控制器
[root@k8s-master01 9]# kubectl delete deployment --all
deployment.extensions "myapp-deploy" deleted
[root@k8s-master01 9]# kubectl get pod
No resources found.
# 2、容忍master01节点的污点,结合节点亲和性的硬亲和,实现让pod仅在设置对应污点的节点运行
[root@k8s-master01 9]# vim 2.deployment.yaml
[root@k8s-master01 9]# cat 2.deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: myapp
release: stabel
template:
metadata:
labels:
app: myapp
release: stabel
spec:
containers:
- name: myapp
image: wangyanglinux/myapp:v1
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- k8s-master01
[root@k8s-master01 9]# kubectl apply -f 2.deployment.yaml
deployment.apps/myapp-deploy created
# 3、查看所有运行的pod,都在master01节点,此时master01节点存在污点
[root@k8s-master01 9]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp-deploy-59dc7d6fc6-2w7mq 1/1 Running 0 8s 172.100.0.13 k8s-master01 <none> <none>
myapp-deploy-59dc7d6fc6-dzxbb 1/1 Running 0 8s 172.100.0.12 k8s-master01 <none> <none>
myapp-deploy-59dc7d6fc6-h6kgj 1/1 Running 0 8s 172.100.0.11 k8s-master01 <none> <none>
[root@k8s-master01 9]# kubectl describe node k8s-master01|grep Taint
Taints: node-role.kubernetes.io/master:NoSchedule
注意:数据库类pod
最好在固态盘所在节点运行,机械盘也行-----软亲和
四、指定调度节点
1、Pod.spec.nodeName
会跳过 Scheduler 的调度策略,该匹配规则是强制匹配
可限制范围小,优先级高。有污点的节点,没有容忍也能运行,但仍会经过预选、优选
实验:在指定节点上运行
在master节点需要容忍才能运行pod,用 Pod.spec.nodeName 选项,没有容忍也能运行
# 写一个 3.deployment.yaml 文件,让控制器的pod都在k8s-master01中运行,此时k8s-master01节点存在污点
# 核心选项: nodeName: k8s-master01
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: myweb
spec:
replicas: 3
template:
metadata:
labels:
app: myweb
spec:
nodeName: k8s-master01
containers:
- name: myweb
image: wangyanglinux/myapp:v1
ports:
- containerPort: 80
实验步骤:
Ⅰ、清理基于当前目录所有的yaml创建的资源对象
$ ck8s .
ck8s 命令是编写的一个脚本 命令.md
Ⅱ、基于3.deployment.yaml 文件,创建控制器
实现仅在 k8s-master01 节点运行pod(为对污点进行容忍)
[root@k8s-master01 9]# vim 3.deployment.yaml
[root@k8s-master01 9]# cat 3.deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: myweb
spec:
replicas: 3
template:
metadata:
labels:
app: myweb
spec:
nodeName: k8s-master01
containers:
- name: myweb
image: wangyanglinux/myapp:v1
ports:
- containerPort: 80
[root@k8s-master01 9]# kubectl apply -f 3.deployment.yaml
deployment.extensions/myweb created
[root@k8s-master01 9]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myweb-7bf59c5ff5-75h2n 1/1 Running 0 4s 172.100.0.14 k8s-master01 <none> <none>
myweb-7bf59c5ff5-pttjs 1/1 Running 0 4s 172.100.0.16 k8s-master01 <none> <none>
myweb-7bf59c5ff5-swtlq 1/1 Running 0 4s 172.100.0.15 k8s-master01 <none> <none>
2、Pod.spec.nodeSelector
标签选择器会经过 scheduler 调度,需要匹配(若节点有污点,需要容忍才能运行)
实验:测试 Pod.spec.nodeSelector 选项
4.deployment,yaml 文件中,加入指定调度节点的标签选择,未设置对污点的容忍
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: myweb
spec:
replicas: 3
template:
metadata:
labels:
app: myweb
spec:
nodeSelector:
hardware: GPU
containers:
- name: myweb
image: wangyanglinux/myapp:v1
实验步骤:
Ⅰ、给存在污点的master01节点加入标签
[root@k8s-master01 9]# kubectl label node k8s-master01 hardware=GPU
[root@k8s-master01 9]# kubectl get node --show-labels|grep hardware
k8s-master01 Ready master 27d v1.15.1 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,hardware=GPU,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-master01,kubernetes.io/os=linux,node-role.kubernetes.io/master=
Ⅱ、根据 4.deployment.yaml 创建控制器
[root@k8s-master01 9]# ck8s .
[root@k8s-master01 9]# vim 4.deployment.yaml
[root@k8s-master01 9]# cat 4.deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: myweb
spec:
replicas: 3
template:
metadata:
labels:
app: myweb
spec:
nodeSelector:
hardware: GPU
containers:
- name: myweb
image: wangyanglinux/myapp:v1
[root@k8s-master01 9]# kubectl apply -f 4.deployment.yaml
# 发现无法创建,需要容忍master节点的污点
[root@k8s-master01 9]# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
myweb 0/3 3 0 23s
[root@k8s-master01 9]# kubectl get pod
NAME READY STATUS RESTARTS AGE
myweb-84fbbb4465-gw8kc 0/1 Pending 0 46s
myweb-84fbbb4465-rxx6l 0/1 Pending 0 46s
myweb-84fbbb4465-v9brc 0/1 Pending 0 46s
Ⅲ、创建新的文件 5.deployment.yaml ,其中加入对污点的容忍
[root@k8s-master01 9]# vim 5.deployment.yaml
[root@k8s-master01 9]# cat 5.deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: myweb
spec:
replicas: 3
template:
metadata:
labels:
app: myweb
spec:
nodeSelector:
hardware: GPU
containers:
- name: myweb
image: wangyanglinux/myapp:v1
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
Ⅳ、基于 5.deployment.yaml 运行控制器
[root@k8s-master01 9]# kubectl apply -f 5.deployment.yaml
# 发现在master01节点运行pod成功
[root@k8s-master01 9]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myweb-5f844c857b-crddz 1/1 Running 0 26s 172.100.0.21 k8s-master01 <none> <none>
myweb-5f844c857b-rzncw 1/1 Running 0 26s 172.100.0.20 k8s-master01 <none> <none>
myweb-5f844c857b-sbpp7 1/1 Running 0 23s 172.100.0.22 k8s-master01 <none> <none>